








服務熱線
0755-83044319

發布時間:2025-02-20作者來源:薩科微瀏覽:2009
一、引子
最近拜讀了《DeepSeek-R1: Incentivizing Reasoning Capability in LLMs viaReinforcement Learning》,該論文討論了DeepSeek-R1模型,該模型旨在通過強化學習(RL)提升大語言模型(LLM)的推理能力。

DeepSeek-R1 和 DeepSeek-R1-Zero 模型:
DeepSeek-R1-Zero 通過純強化學習訓練,完全不依賴于監督微調(SFT)。該模型展示了令人印象深刻的推理能力,如自我驗證和反思,但存在可讀性差和語言混合等問題。
為了解決這些問題,DeepSeek-R1 引入了多階段訓練流程,首先使用冷啟動數據對基礎模型進行微調,然后使用推理導向的強化學習(RL)和監督微調(SFT)。這種方法提高了模型的可讀性和性能,使其在推理任務上達到與OpenAI模型(如OpenAI-o1-1217)相當的水平。
推理能力的蒸餾:
論文探索了如何將大模型(如DeepSeek-R1)學到的推理模式蒸餾到小模型中。這一蒸餾方法使得小模型在推理任務上表現出色,超越了一些[敏感詞]的模型。
從DeepSeek-R1蒸餾出的較小模型(1.5B、7B、14B、32B、70B)在AIME 2024和MATH-500等基準測試上表現良好,為小模型提供了增強推理能力的有效方法,而不需要直接進行RL訓練。
模型評估與基準測試:
DeepSeek-R1在多個推理任務上的表現進行了評估,包括AIME 2024、MATH-500、Codeforces等。DeepSeek-R1在數學推理和編程任務中表現出色,在多個任務中超過了現有的OpenAI模型(如o1-1217)。
蒸餾后的模型在這些基準測試上也取得了競爭力的成績,像DeepSeek-R1-Distill-Qwen-7B這樣的較小模型超過了QwQ-32B-Preview等模型。
挑戰與未來工作:
盡管DeepSeek-R1取得了成功,但它仍面臨一些挑戰,如語言混合問題以及對提示結構(尤其是少量樣本提示)的敏感性。此外,模型在軟件工程任務上的能力仍然有限,因為在此類領域進行RL訓練效率較低。
未來的工作將集中在改善語言一致性、增強非推理任務的表現,并優化RL應用以提高在軟件工程任務中的性能。
該論文的關鍵創新點在于使用強化學習直接訓練大語言模型的推理能力,繞過了監督數據的需求,同時成功地將推理能力蒸餾到較小的模型中。
三、摘要
論文摘要:簡潔地介紹了兩款推理模型:DeepSeek-R1-Zero 和 DeepSeek-R1,它們的主要特點和發展過程如下:
DeepSeek-R1-Zero:
這是[敏感詞]代推理模型,采用了大規模的強化學習(RL)進行訓練,而沒有使用監督微調(SFT)作為前期步驟。通過強化學習,DeepSeek-R1-Zero 自然地展現出了強大的推理能力,能夠完成許多復雜的推理任務。但它也存在一些問題,比如可讀性差,且有時會出現語言混合的問題。
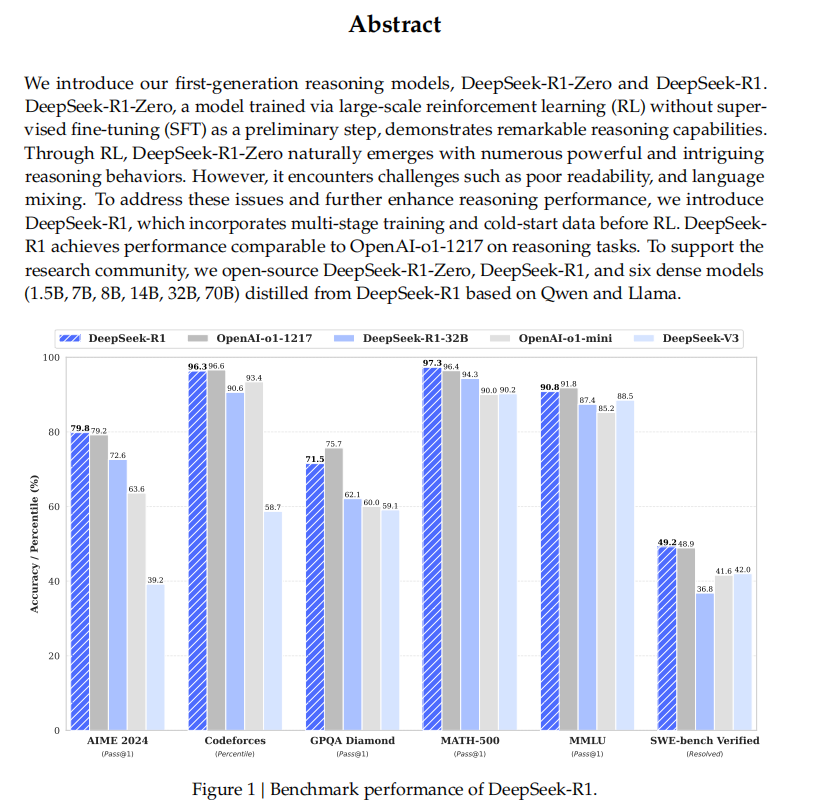
DeepSeek-R1:
為了解決 DeepSeek-R1-Zero 中的這些問題,作者引入了 DeepSeek-R1,這款模型在強化學習之前加入了多階段訓練和冷啟動數據(即使用一些初步的標注數據進行訓練),從而提高了推理能力和模型的可讀性。最終,DeepSeek-R1 的推理表現與 OpenAI-o1-1217 相當。
開源貢獻:為了支持科研社區,作者開源了DeepSeek-R1-Zero、DeepSeek-R1 以及從 DeepSeek-R1 蒸餾出來的六個較小模型(參數規模分別為 1.5B、7B、8B、14B、32B 和 70B),這些模型基于 Qwen 和 Llama。
四:目錄和正文

①Introduction:簡要說明了近年來大型語言模型(LLMs)的發展,特別是推理能力的提升。
語言模型的快速發展:
近年來,大型語言模型(LLMs)在不斷更新迭代,逐漸縮小了與人工通用智能(AGI)的差距。AGI指的是可以像人類一樣處理任何任務的智能系統。
后期訓練(Post-training):
后期訓練已成為模型訓練流程中的一個重要環節。它能夠提升模型在推理任務上的準確性,同時與社會價值對齊,適應用戶的需求,而且相對于前期訓練所需的計算資源要少得多。
推理能力的挑戰:
OpenAI的模型通過增加“思維鏈”(Chain-of-Thought, CoT)的長度,在推理任務中取得了顯著的進展。這種方法幫助模型在數學、編程和科學推理等領域取得了顯著成效。但如何在測試時擴展推理能力仍然是一個開放的問題。
提出的創新方法:
該論文提出了一種通過強化學習(RL)直接提升語言模型推理能力的方法,不依賴于任何監督數據(即不使用標注數據進行訓練)。他們使用一個名為DeepSeek-V3-Base的基礎模型,并用GRPO(一種強化學習算法)框架來提升推理表現。
在訓練過程中,DeepSeek-R1-Zero(該模型的[敏感詞]個版本)表現出強大的推理行為,經過數千次的強化學習訓練,它在推理任務上的表現顯著提升。例如,在AIME 2024基準測試中的得分從最初的15.6%提升到71.0%,通過多數投票后,得分進一步提升至86.7%,達到了與OpenAI的模型o1-0912相當的水平。
遇到的挑戰和優化:
盡管DeepSeek-R1-Zero表現優秀,但它的可讀性較差,且有時會出現語言混合的問題。為了改善這些問題,論文作者引入了DeepSeek-R1模型,采用了多階段訓練和冷啟動數據(即使用一些初步數據進行訓練)來進一步提高推理能力。
訓練過程中,首先使用冷啟動數據對基礎模型進行微調,然后進行推理導向的強化學習(與DeepSeek-R1-Zero類似)。接著,創建新的數據集來進行監督微調,并將其用于訓練模型,最后再進行一次強化學習訓練,從而得到DeepSeek-R1,其推理能力與OpenAI的模型相當。
蒸餾技術的探索:
論文還探討了從DeepSeek-R1蒸餾(提取)推理能力到更小的模型。通過直接蒸餾,使用較小的基礎模型(例如Qwen2.5-32B)獲得的效果比直接應用強化學習更好。
通過這種蒸餾方法,作者成功提升了較小模型(如14B和32B)的推理能力,并在推理基準測試中創下了新紀錄。
Contributions:總結了模型在各類任務中的評估結果。以下是對該部分的解讀:
后期訓練與強化學習(RL)應用:
論文的一個關鍵創新是,DeepSeek-R1 通過直接應用強化學習(RL)在基礎模型上進行訓練,而不依賴傳統的監督微調(SFT)。這種方法允許模型通過“思維鏈”(Chain-of-Thought, CoT)來解決復雜問題,推動了 DeepSeek-R1-Zero 的發展。
DeepSeek-R1-Zero 展現了自我驗證、反思能力和生成長思維鏈的能力,這標志著在推理任務中的一個重要進步。
這是首次通過純粹的RL方法提升大語言模型的推理能力,而不需要監督微調(SFT),為未來的研究開辟了新方向。
DeepSeek-R1模型的改進:
DeepSeek-R1 在 DeepSeek-R1-Zero 的基礎上進行了進一步改進,引入了多階段訓練和冷啟動數據,優化了模型的推理能力,并且增加了與人類偏好對齊的強化學習階段,同時繼續使用 SFT 階段來優化模型的推理和非推理能力。
這個改進的流程能夠為業界帶來更好的推理能力,提升模型的普適性和效果。
蒸餾技術的應用:
論文還展示了如何將較大模型的推理模式蒸餾到更小的模型中,并證明蒸餾出的較小模型在推理任務中比直接通過RL訓練的小模型表現更好。
使用 DeepSeek-R1 生成的推理數據,作者對多個常用的稠密模型進行了微調,結果顯示這些蒸餾后的模型在基準測試中表現異常優秀,超過了之前一些開放源代碼模型的表現。
比如,DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 基準測試中達到了 55.5% 的 Pass@1,超越了 QwQ-32B-Preview。另外,DeepSeek-R1-Distill-Qwen-32B 在多個測試中也有很好的表現,分別在 AIME 2024 和 MATH-500 上取得了 72.6% 和 94.3%的成績。
推理任務:
DeepSeek-R1 在 AIME 2024 上取得了 79.8% 的 Pass@1,略微超過了 OpenAI 的 o1-1217。在 MATH-500 上,表現十分出色,達到了 97.3%,與 OpenAI 的 o1-1217 相當。
在編程相關任務上,DeepSeek-R1 的表現堪稱專家級,在 Codeforces 上達到了 2029 的 Elo 評分,超越了 96.3%的參賽者。
知識處理能力:
在多個知識類基準測試(如 MMLU、MMLU-Pro 和 GPQA Diamond)中,DeepSeek-R1 的表現超過了 DeepSeek-V3,在 MMLU 上得分為 90.8%,在 GPQA Diamond 上為 71.5%。雖然在這些基準測試上稍微遜色于 OpenAI-o1-1217,但 DeepSeek-R1 的表現仍然優于其他閉源模型,顯示出它在教育任務上的競爭力。
在事實性問題的基準測試 SimpleQA 上,DeepSeek-R1 超越了 DeepSeek-V3,展現了其處理事實性問題的能力。
其他任務:
DeepSeek-R1 在創意寫作、問答、編輯、總結等任務中也表現出色,特別是在非考試類任務上,展示了其強大的處理能力。比如,在 AlpacaEval 2.0 上,它以 87.6%的長度控制勝率表現出色,在 ArenaHard 上的勝率為 92.3%。
另外,DeepSeek-R1 在需要長上下文理解的任務中,顯著超越了 DeepSeek-V3,表現出了它在處理長文本方面的優勢。小結
DeepSeek-R1 模型通過引入強化學習(RL)和蒸餾技術,顯著提升了推理能力,并且在多個任務中超過了之前的模型,尤其是在數學、編程和知識處理等領域。
論文中展示的多階段訓練方法和冷啟動數據的結合,以及推理能力的蒸餾方法,為未來語言模型的發展提供了新的思路和技術路徑。
②Approach:詳細闡述了 DeepSeek-R1 和 DeepSeek-R1-Zero 的訓練方法和過程,尤其是通過強化學習(RL)提升推理能力的具體步驟。以下是該部分的解讀:
過去的工作通常依賴大量的監督數據來提升模型性能,而本文展示了即使沒有監督微調(SFT)數據,通過大規模的強化學習(RL)也能顯著提升推理能力。
通過這種方法,模型能夠自我演化,并通過強化學習學習到推理模式。具體來說,本文介紹了以下三個關鍵步驟:
DeepSeek-R1-Zero:直接對基礎模型應用強化學習(RL),而不使用任何監督微調數據。
DeepSeek-R1:在經過長鏈思維(Chain-of-Thought,CoT)示例微調的檢查點基礎上應用RL。
蒸餾:將 DeepSeek-R1 的推理能力蒸餾到較小的稠密模型中。
為了節省訓練成本,作者采用了 Group Relative Policy Optimization (GRPO) 算法。這種算法避免了使用與策略模型大小相同的評論模型(critic model),而是通過對一組輸出結果進行評分來估計基線。
具體來說,GRPO 對每個問題通過從舊的策略模型中抽取一組輸出進行優化,并通過[敏感詞]化預設目標來優化策略模型。
獎勵系統 是強化學習中的核心,決定了優化方向。為了訓練 DeepSeek-R1-Zero,作者設計了兩種獎勵:
準確度獎勵(Accuracy rewards):評估模型的回答是否正確。例如,對于數學題,模型必須以特定格式給出最終答案,以便通過規則驗證其正確性。
格式獎勵(Format rewards):強制模型將其思維過程置于 <think> 和 </think> 標簽之間,這有助于結構化推理過程并保持格式一致性。
作者沒有使用基于神經網絡的獎勵模型,因為這可能導致獎勵作弊(reward hacking),而且重新訓練獎勵模型會消耗大量計算資源。
在訓練 DeepSeek-R1-Zero 時,作者設計了一個簡單的模板,要求模型首先生成思維過程,然后給出最終答案。這個模板避免了內容特定的偏見,如強制要求反思性推理或采用特定的解題策略,目的是準確地觀察模型在強化學習過程中的自然進展。
DeepSeek-R1-Zero 在 AIME 2024 基準測試中的表現逐步提升,Pass@1 分數從 15.6% 提升到 71.0%,并最終通過多數投票進一步提高到 86.7%,超越了 OpenAI-o1-0912 的表現。
DeepSeek-R1-Zero 展示了在沒有監督微調數據的情況下,通過強化學習(RL)獲得強大推理能力的能力,這證明了其自我學習和推廣的潛力。
強化學習通過增強 DeepSeek-R1-Zero 的推理能力,使其能夠有效解決各種復雜問題。此外,通過使用多數投票,模型的推理結果變得更加可靠,進一步提高了其性能。
這一部分展示了 DeepSeek-R1-Zero 如何通過強化學習(RL)自主提高其推理能力,而無需監督微調(SFT)。
由于強化學習直接從基礎模型開始,我們可以清晰地觀察模型在訓練過程中的變化,特別是在處理復雜推理任務方面的進展。
模型思考時間的增加:
隨著訓練的進行,DeepSeek-R1-Zero 在回答問題時的推理時間(即生成的推理步驟長度)逐步增加。
這表明模型在處理推理任務時,會主動延長思考時間,以解決更復雜的問題。
這種增長并不是通過人為調整參數實現的,而是模型在強化學習環境中自主發展的能力。
自發行為的出現:
反思(Reflection):模型會回顧并重新評估自己的推理步驟,類似于人類在解題時發現錯誤后進行修正的行為。
探索不同解法:模型會嘗試多種方法來解決同一個問題,而不是只遵循固定的套路。
這些行為并不是人為編碼的規則,而是模型在強化學習過程中自發涌現的能力,這也是強化學習的強大之處。
論文提到了訓練過程中出現的一個有趣現象,被稱為 "Aha Moment"(頓悟時刻)。
在某個訓練階段,DeepSeek-R1-Zero 突然學會了重新審視自己的解題過程,并在必要時調整思維策略。
這一行為類似于人類在解題時,突然意識到之前的思路可能有問題,從而停下來重新思考。
這種行為表明,強化學習不僅可以提高模型的推理能力,還可以讓模型在沒有明確指導的情況下,自主發展出更高級的解題策略。
這種能力不是通過硬編碼規則實現的,而是模型在強化學習環境中通過試錯學習到的,這說明強化學習有助于推動人工智能向更高級的智能水平發展。
研究人員在觀察到這個現象時,也感到驚喜,因為這表明強化學習能夠引導 AI 發展出意想不到的智能行為。
盡管 DeepSeek-R1-Zero 展示了強大的推理能力,并能夠自主發展復雜的思維模式,但它仍然存在一些問題:
可讀性差:
由于模型主要關注推理能力,而不是語言表達,最終生成的推理過程可能不夠清晰,難以閱讀和理解。
語言混合:
由于訓練過程中涉及多種語言,DeepSeek-R1-Zero 可能會在推理過程中混合使用不同的語言,使得輸出內容難以解析。
為了解決 DeepSeek-R1-Zero 在可讀性和語言混合方面的問題,研究團隊開發了 DeepSeek-R1。
DeepSeek-R1 結合了強化學習和人類友好的冷啟動數據(cold-start data),使得推理過程更加清晰,輸出更易閱讀,同時減少語言混合的問題。
DeepSeek-R1-Zero 通過強化學習自主提升推理能力,能夠在沒有監督數據的情況下發展出復雜的推理策略,如反思和多種解題方法。
“頓悟時刻” 證明了 AI 在強化學習的引導下可以產生自發的智能行為,進一步提升了 AI 在推理任務中的表現。
DeepSeek-R1-Zero 的局限性:可讀性較差,且在推理過程中可能會混用多種語言,影響理解。
解決方案:DeepSeek-R1 采用更友好的冷啟動數據,以提高可讀性并減少語言混合問題。
這部分內容突出了強化學習的潛力,以及 AI 在無監督環境下如何通過試錯進化出更強的推理能力,同時也展現了強化學習在 AI 研究中的突破性貢獻。
這部分內容詳細介紹了 DeepSeek-R1 模型的訓練方法,特別是通過冷啟動數據(cold start)和強化學習(RL)來提升推理能力的過程。以下是該部分的詳細解讀:
在 DeepSeek-R1-Zero 的基礎上,研究者提出了通過引入冷啟動數據來加速推理性能的提升。兩大關鍵問題是:
如何通過引入少量高質量數據來加速推理性能的提高或訓練收斂的速度?
如何訓練一個既能清晰表達推理過程(CoT),又具備強大通用能力的用戶友好模型?
為了回答這些問題,作者設計了一個包含四個階段的訓練流程,用于訓練 DeepSeek-R1。
在 DeepSeek-R1 的訓練中,冷啟動數據的引入起到了關鍵作用,尤其是在 DeepSeek-R1-Zero 的早期不穩定訓練階段。研究者收集了一些長鏈思維(CoT)數據,并用這些數據對基礎模型進行微調,作為強化學習的初始步驟。
冷啟動數據的收集方式:
使用少量示例提示(few-shot prompting)生成長鏈思維。
直接提示模型生成詳細的答案,并加入反思和驗證步驟。
從 DeepSeek-R1-Zero 的輸出中收集數據,并通過人工后處理優化結果。
冷啟動數據的優勢:
可讀性:相比 DeepSeek-R1-Zero 生成的難以閱讀的推理過程,DeepSeek-R1 在生成冷啟動數據時,設計了更易讀的格式,每個回答結尾都有一個總結部分,并過濾掉不易閱讀的內容。
潛力:通過精心設計冷啟動數據模式,DeepSeek-R1 在性能上優于 DeepSeek-R1-Zero,證明了這種迭代訓練方法的有效性。
在對基礎模型進行冷啟動微調后,作者使用與 DeepSeek-R1-Zero 相同的大規模強化學習(RL)訓練方法,進一步提升推理能力,尤其在數學、編程、科學和邏輯推理等任務上。
語言混合問題:在強化學習訓練過程中,常常出現語言混合的問題,尤其是在多語言提示的情況下。為了解決這個問題,研究者引入了語言一致性獎勵,即在推理過程中鼓勵模型保持目標語言的一致性。
獎勵機制:通過結合推理任務的準確度獎勵和語言一致性獎勵,模型不斷優化,最終達到了在推理任務上的收斂。
拒絕采樣(Rejection Sampling):當推理導向的強化學習訓練收斂后,研究者使用該檢查點收集監督微調(SFT)數據,進一步改進模型的表現。
推理數據:通過拒絕采樣從 RL 訓練的檢查點生成推理數據,并對生成的數據進行人工篩選,確保數據的高質量。
非推理數據:包括寫作、事實性問答、自我認知和翻譯等任務,結合 DeepSeek-V3 的數據進行微調。
為了進一步提高模型對人類偏好的適應性,作者實施了第二階段的強化學習,旨在優化模型的有用性和無害性,同時繼續完善推理能力。
有用性:重點確保模型的回答對用戶有實際幫助,評估時僅關注最終總結部分。
無害性:評估整個回答的內容,識別并消除潛在的偏見或有害內容。
為了讓更小的模型具備推理能力,作者采用了蒸餾方法,將 DeepSeek-R1 的推理能力傳遞給更小的模型。
研究者將 DeepSeek-R1 用來微調開源的模型如 Qwen 和 Llama,并使用約 80 萬個訓練樣本進行蒸餾。實驗表明,這種蒸餾方法顯著提升了小模型的推理能力。
通過簡單的蒸餾方法,小模型如 Qwen 和 Llama 的推理能力得到了極大的增強。雖然作者并未在蒸餾后的模型中使用強化學習(RL),但他們認為這項工作展示了蒸餾技術的有效性,并為未來的強化學習探索留給了廣泛的研究社區。
小結。這部分介紹了 DeepSeek-R1 的訓練流程,強調了通過引入冷啟動數據和強化學習(RL)來提升推理能力的重要性。通過設計冷啟動數據,解決了 DeepSeek-R1-Zero 中的可讀性問題,并通過強化學習進一步優化模型的推理能力和語言一致性。此外,作者還展示了將 DeepSeek-R1 的推理能力蒸餾到更小模型中的有效性,這一過程證明了蒸餾技術在提升推理能力方面的巨大潛力。
③Experiment:詳細介紹了 DeepSeek-R1 和蒸餾后的模型在多個基準測試上的評估方法和實驗設置。
評估任務:作者在多個標準基準測試上評估了模型的表現,涵蓋了不同領域的任務,包括推理、編程、數學、問答等。具體的測試基準包括:
MMLU、MMLU-Redux、MMLU-Pro、C-Eval、CMMLU、SimpleQA、AIME 2024、Codeforces 等。
開放式生成任務:如 AlpacaEval 2.0 和 Arena-Hard,這些任務使用 GPT-4-Turbo-1106 作為評估判定者,進行對比分析。
數據集:對于代碼和數學相關的基準測試,使用了 HumanEval-Mul 數據集,涵蓋了包括 Python、Java、C++、JavaScript 等在內的八種主流編程語言。
評價方法:實驗中對不同模型進行了廣泛的評估,主要包括推理任務(如數學、編程和科學推理)以及開放生成任務。蒸餾模型的表現也在 AIME 2024、MATH-500、Codeforces 等基準上進行了測試。
標準基準測試的評估設置:使用了 DeepSeek-V3 中的提示,并結合 simpleevals 框架進行標準基準測試的評估。針對一些特殊的基準(如 MMLU-Redux 和 MMLU-Pr),作者修改了原始的提示格式,使用零樣本(zero-shot)設置進行評估。
推理任務的評估:對于推理任務(如數學、編程等),評估使用了基于 Chain-of-Thought(CoT)格式的提示。不同任務根據其特點調整了提示格式,以確保能夠準確評估模型的推理能力。
生成長度限制:設置了[敏感詞]生成長度為 32,768 個標記(tokens),確保模型在生成長文本時不會被截斷。
解碼方法:為了避免使用貪婪解碼(greedy decoding)導致的高重復率和不同檢查點之間的顯著變化,實驗中采用了 pass@k 評估方法。具體來說,使用了非零溫度(temperature = 0.6)和top-p 采樣(top-p = 0.95)來生成多個(通常是 4 到 64 個)響應,并計算 pass@1 的得分。
結果評估:
Pass@k:對于每個問題,生成多個響應,計算其中正確響應的比例(pass@1),這種方法可以提供更可靠的性能估計。
共識投票(Consensus Voting):對于 AIME 2024 基準測試,使用 64 個樣本進行多數投票(cons@64)計算,從而提高評估的穩定性和可靠性。
基準比較:作者與多個強基準模型進行了比較,包括 DeepSeek-V3、Claude-Sonnet-3.5、GT-40-0513、OpenAI-o1-mini、OpenAI-o1-1217 等,展示了 DeepSeek-R1 和蒸餾模型的表現。
蒸餾模型的表現:對于蒸餾模型(如 Qwen 和 Llama),在 AIME 2024、MATH-500、Codeforces 等基準上報告了代表性的結果。
Pass@1 和共識投票:通過使用 pass@1 和 cons@64 評估方法,模型在多個推理任務中的表現得到了更加穩定和可靠的評估。
基準測試的綜合評估:通過多種標準的推理基準測試,證明了 DeepSeek-R1 及其蒸餾模型在推理任務中的強大能力,特別是在數學、編程、邏輯推理等任務上表現突出。
這部分內容展示了 DeepSeek-R1 模型在多個基準測試中的評估結果,并與其他代表性模型進行了比較。以下是詳細解讀:
DeepSeek-R1 在與 DeepSeek-V3 的比較中,顯示出顯著的性能提升,尤其是在 STEM(科學、技術、工程和數學) 相關問題上。通過大規模強化學習(RL)訓練,模型在這些領域取得了顯著的準確性提高。
FRAMES 基準:這是一個長上下文依賴的問答任務,DeepSeek-R1 在此任務中表現出色,展示了其強大的文檔分析能力,表明推理模型在 AI 驅動的搜索和數據分析任務中具有潛力。
在 SimpleQA 這一基準測試上,DeepSeek-R1 超過了 DeepSeek-V3,證明了其在處理事實性查詢方面的能力。類似地,OpenAI的 o1 系列模型在這一基準測試上也優于 GPT-4o。
然而,DeepSeek-R1 在中文版本的 SimpleQA 測試中表現不佳,原因是它在安全強化學習(RL)后傾向于拒絕回答某些查詢。沒有應用安全 RL 時,DeepSeek-R1 的準確率可以超過 70%。
IF-Eval 基準測試衡量了模型執行格式指令的能力,DeepSeek-R1 在此基準上表現優秀。其提升與最終階段的監督微調(SFT)和強化學習(RL)數據的加入密切相關。
在 AlpacaEval 2.0 和 ArenaHard 等開放領域問題回答任務中,DeepSeek-R1 同樣展現了強大的寫作能力和開放領域問答能力,遠超 DeepSeek-V3,并且其生成的總結文本避免了長度偏差,生成的平均長度為 689 tokens(ArenaHard)和 2,218 characters(AlpacaEval 2.0)。
在數學任務中,DeepSeek-R1 的表現與 OpenAI-o1-1217 相當,顯著超過了其他模型。
在編程算法任務上(如 LiveCodeBench 和 Codeforces),推理導向的模型(如 DeepSeek-R1)主導了這些基準測試,證明了推理能力對編程任務的有效支持。
在面向工程的編程任務(如 Aider 和 SWE Verified)中,OpenAI-o1-1217 在 Aider 上表現優于 DeepSeek-R1,但在 SWE Verified 上與 DeepSeek-R1 的表現相當。隨著更多相關的強化學習訓練數據的加入,預計 DeepSeek-R1 在工程任務中的表現將進一步提升。
DeepSeek-R1 蒸餾模型(如 DeepSeek-R1-7B, DeepSeek-R1-14B, DeepSeek-R1-32B, 和 DeepSeek-R1-70B)在推理相關的基準測試中表現突出,超越了非推理導向模型(如 GPT-4-0513)以及其他一些強基準模型:
DeepSeek-R1-7B 超過了 GPT-4-0513。
DeepSeek-R1-14B 在所有評估指標上超越了 QwQ-32B-Preview。
DeepSeek-R1-32B 和 DeepSeek-R1-70B 在大多數基準上顯著超過了 OpenAI-o1-mini。
研究還發現,將強化學習(RL)應用于蒸餾后的模型,會帶來顯著的性能提升。盡管目前的實驗只展示了簡單的 SFT 蒸餾 結果,作者認為這為進一步探索 RL 在蒸餾模型中的應用提供了一個重要的研究方向。
DeepSeek-R1 在多個教育和推理基準上表現出色,特別是在 STEM 領域、長文檔分析(FRAMES)和事實性問答(SimpleQA)方面相較于 DeepSeek-V3 提升顯著。
在數學、編程和開放領域問題回答任務中,DeepSeek-R1 展現了強大的推理能力,特別是在 LiveCodeBench 和 Codeforces 等編程基準測試中表現突出。
蒸餾技術在小模型中表現出色,DeepSeek-R1 的蒸餾模型超越了許多傳統非推理模型,并通過進一步結合強化學習,進一步提升了推理能力。
這表明,通過強化學習的應用和蒸餾技術,DeepSeek-R1 在多任務和多個領域中展示了廣泛的適用性和強大的性能。
④Discussion:討論了 DeepSeek-R1 在開發過程中遇到的一些挑戰、嘗試的失敗方法以及與蒸餾技術和強化學習(RL)之間的對比。以下是詳細解讀:
在 DeepSeek-R1 的開發過程中,作者探索了兩種主要的提升模型推理能力的方法:蒸餾(Distillation)和 強化學習(RL)。
通過對 Qwen-32B-Base 進行大規模強化學習訓練,作者開發了 DeepSeek-R1-Zero-Qwen-32B,并進行了評估。實驗結果表明,雖然強化學習訓練的 DeepSeek-R1-Zero-Qwen-32B 在推理基準測試中的表現與 QwQ-32B-Preview 相當,但通過蒸餾得到的 DeepSeek-R1-Distill-Qwen-32B 在所有基準測試中表現更好,遠超強化學習訓練得到的版本。
結論:
蒸餾較強大的模型到較小模型中能夠產生優異的結果,而僅依靠大規模強化學習的小模型需要巨大的計算資源,并且可能無法達到蒸餾方法的效果。
盡管蒸餾策略既經濟又有效,但如果要進一步推動智能水平的發展,可能還需要更強大的基礎模型和更大規模的強化學習訓練。
過程獎勵模型(PRM) 是一種引導模型解決推理任務的合理方法,通過獎勵模型來促進模型的推理過程。然而,實踐中存在一些主要限制:
步驟定義困難:很難為一般推理任務明確地定義每個小步驟。
正確性判定困難:判斷當前步驟是否正確是一項具有挑戰性的任務,尤其是自動注釋可能無法得到令人滿意的結果,而人工標注又難以擴展。
獎勵作弊問題:引入基于模型的獎勵模型不可避免地會導致“獎勵作弊”(reward hacking),即模型會利用獎勵機制本身的漏洞來優化結果,而這需要額外的訓練資源,并且會使訓練流程更加復雜。
結論:盡管PRM可以幫助重新排序模型生成的前N個響應,或輔助引導搜索,但與在大規模強化學習過程中引入的額外計算開銷相比,其優勢是有限的。
蒙特卡洛樹搜索(MCTS) 是受 AlphaGo 和 AlphaZero 啟發的方法,目的是通過系統地探索解空間來提升推理能力。
挑戰:
與棋類游戲不同,MCTS 在文本生成中的搜索空間大得多,因此在擴展每個節點時會遇到困難,容易導致模型陷入局部最優解。
價值模型的訓練難度:在 AlphaGo 中,通過訓練價值模型不斷提升模型性能,但在 MCTS 的文本生成任務中,訓練一個細粒度的價值模型非常困難,這使得模型難以迭代提升性能。
訓練過程:通過引導模型生成多個標簽來對應每個推理步驟,使用收集的提示進行 MCTS 搜索,然后通過生成的問答對訓練模型。
結論:
MCTS 可以在推理時提升性能,尤其是在與預訓練的價值模型配對時。然而,要通過自我搜索不斷提升模型性能仍然是一個巨大的挑戰,尤其是在文本生成任務中的復雜性更高。小結如下:
蒸餾 vs 強化學習:雖然 蒸餾 在將強大模型的推理能力傳遞到較小模型中表現非常好,但大規模強化學習仍然需要大量計算資源,且不一定能達到蒸餾的效果。為了進一步推動智能的發展,可能還需要更強的基礎模型和更大規模的強化學習。
失敗的嘗試:
過程獎勵模型(PRM) 在實際應用中面臨定義困難、正確性判斷問題以及獎勵作弊等問題,導致其在大規模強化學習中表現不佳。
蒙特卡洛樹搜索(MCTS) 盡管在理論上有提升潛力,但在文本生成任務中,由于生成空間龐大、價值模型訓練困難,最終在模型性能提升上仍面臨挑戰。
本研究展示了通過強化學習(RL)增強大語言模型推理能力的過程:
DeepSeek-R1-Zero:這是一種純粹的 RL 方法,無需冷啟動數據,能夠在多個任務上實現強大的性能。
DeepSeek-R1:相比于 DeepSeek-R1-Zero,DeepSeek-R1 在利用冷啟動數據和迭代的 RL 微調后,表現更為強大,最終在多個任務上達到了與 OpenAI-o1-1217 相當的性能水平。
此外,論文還探索了將推理能力蒸餾到小型稠密模型中:
DeepSeek-R1 作為教師模型生成了 80 萬個訓練樣本,并對多個小型稠密模型進行了微調,結果非常有希望:例如 DeepSeek-R1-Distill-Qwen-1.5B 在數學基準測試上超越了 GPT-4o 和 Claude-3.5-Sonnet,在 AIME 上達到了 28.9%,在 MATH 上達到了 83.9% 的成績。
這些結果表明,蒸餾技術在小模型中取得了顯著的推理能力提升。
盡管 DeepSeek-R1 取得了令人印象深刻的進展,但仍存在一些局限性:
通用能力不足:目前 DeepSeek-R1 在某些任務上(如函數調用、多輪復雜角色扮演和 JSON 輸出等)能力仍不及 DeepSeek-V3。未來計劃通過使用長鏈思維(CoT)來提升這些領域的任務表現。
語言混合問題:DeepSeek-R1 目前對中文和英文進行了優化,但在處理其他語言的查詢時可能會出現語言混合的問題。例如,在處理非英語或中文的查詢時,推理和回應可能會不自覺地使用英語。未來將致力于解決這一問題。
提示工程問題:在評估 DeepSeek-R1 時,發現模型對提示非常敏感。特別是在使用少量樣本提示(few-shot prompting)時,性能會顯著下降。因此,建議用戶使用零樣本設置(zero-shot setting),直接描述問題并明確指定輸出格式,以獲得[敏感詞]效果。
軟件工程任務:由于 RL 訓練過程中的長時間評估影響了效率,DeepSeek-R1 在軟件工程任務中的應用仍然有限。盡管如此,模型在這類基準測試中的表現未能超越 DeepSeek-V3。未來版本將通過實施軟件工程數據上的拒絕采樣(rejection sampling)或在 RL 過程中的異步評估(asynchronous evaluations)來提高效率,從而解決這一問題。
在未來,研究團隊計劃在以下幾個方面進一步改進 DeepSeek-R1:
通用能力提升:探索如何通過長鏈思維(CoT)來增強 DeepSeek-R1 在復雜角色扮演和其他多輪交互任務中的表現。
解決語言混合問題:提高 DeepSeek-R1 在多語言環境中的穩定性和一致性,避免語言混合的情況。
優化提示工程:進一步研究不同提示(如零樣本和少樣本設置)對模型表現的影響,并制定優化策略,特別是在用戶實際應用時確保其更高的準確性。
增強軟件工程任務能力:通過提高 RL 訓練的效率,例如應用拒絕采樣或異步評估,解決 DeepSeek-R1 在軟件工程任務中的限制。
DeepSeek-R1 在推理任務中的表現顯著提升,尤其是在通過強化學習(RL)和冷啟動數據的結合下,其推理能力超越了傳統模型。蒸餾技術的成功也證明了較小模型同樣可以獲得強大的推理能力。
然而,DeepSeek-R1 在一些高級任務(如復雜角色扮演和軟件工程任務)上仍有不足,未來研究將集中在提高其通用能力和多語言處理能力。
通過進一步優化 RL 過程,解決現有局限性,DeepSeek-R1 有潛力在更多實際應用中取得更大的突破。
免責聲明:本文采摘自“老虎說芯”,本文僅代表作者個人觀點,不代表薩科微及行業觀點,只為轉載與分享,支持保護知識產權,轉載請注明原出處及作者,如有侵權請聯系我們刪除。
友情鏈接:站點地圖 薩科微官方微博 立創商城-薩科微專賣 金航標官網 金航標英文站
Copyright ?2015-2025 深圳薩科微半導體有限公司 版權所有 粵ICP備20017602號
